Steve cradled his pumpkin spice latte as he walked into the office. It had been three weeks since the launch of his HTML5 multiplayer game, and things were going great. As Steve checked his e-mail, he noticed the account statement from his cloud service provider.
“Let’s see here,” Steve muttered to himself. “Virtual server… 100,000 total hours.” Steve knew this was roughly correct, given the statistics they had been gathering. Thinking about the success of the launch, Steve could barely contain his smile. Skimming further down in the statement, Steve froze. All the way at the bottom, nestled between the line for tax and the heading “Bandwidth” was a number that made Steve’s stomach sink as fast as the latte dramatically falling from his hand.
HTML5 games are growing in a strong way. Once Internet Explorer 10 is released, WebSockets will be available in all modern desktop browsers. This technology enables serious realtime communications—the keystone to any non-trivial multiplayer action game. But like a snake in tall grass, bandwidth costs can seemingly come from nowhere. In this article, I want to discuss the oft overlooked cost of network bandwidth and techniques for minimizing it.
The “Hidden” Costs of Network Bandwidth
socket.io is a WebSockets-enabled networking module for node.js I commonly see recommended for its ease of use, robust fallback support, and integrated publish-subscribe pattern. Here is a snippet of server code that demonstrates this.
var io = require('socket.io').listen(80);
io.sockets.on( 'connection', function( socket ) {
io.sockets.emit( 'broadcast', { will: 'be received by everyone' });
socket.on( 'private message', function ( from, msg ) {
console.log( 'I received a private message by', from, 'saying,', msg );
});
});
In just a few short lines, you have a WebSockets implementation that will fallback gracefully into a number of transports at runtime, on a per-client basis. To see the publish-subscribe pattern in action, let’s look at a sample of client code.
var socket = io.connect();
socket.on( 'broadcast', function( data ) {
console.log( data.will === 'be received by everyone' );
});
socket.on( 'connect', function() {
socket.emit( 'private message', 'MyUsername', '"This is easy!"' );
});
The event system used here is familiar to most people, as it is actually EventEmitter found in node.js. All these things are great, so what’s the issue here and what can this small example reveal about why Steve’s bandwidth bill is so high?
JSON: Strengths and Weaknesses
JSON is a way of representing structured data that has enjoyed native
implementations of encoding and decoding in all modern browsers. For
many reasons, JSON has picked up acceptance on the web for data
serialization. If we examine socket.io source, we see that our calls
to emit eventually serialize to JSON. Then, supposing we
inspect the WebSocket frames, we might see the
following.
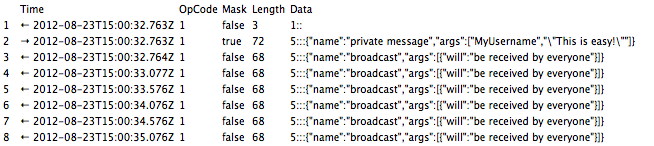
It is generally clear how our calls to emit translate to what we see
here. A lot of that can be attributed to the human-readability of
JSON. However, in a networked game environment where we can expect 20
to 30 messages a second from the server, the verbosity of JSON adds
up. There is a lot of metadata describing the structure of the data
that we don’t want because our priority is compression, rather than
human-readability. We are also not expecting truly arbitrary data, so
the structure that JSON encodes is not necessary. It is becoming clear
that JSON is not the solution for this problem.
Byte Ripper X or (How to Shed Those Bits)
To really understand what we’re dealing with, we will want some real data to play with. For this example, I am going to use the following “game state.”
What we have here could represent the positional and rotational data for two players in a 3D game. The values were made up for this example, but should be sufficient for our purposes. If we were to serialize this game state to JSON, it would be 410 bytes.
And since the camera adds ten pounds, socket.io’s snapshot of the game state adds roughly 30 bytes of overhead on top—more if you have a longer event name. Assuming that we’re sending 30 messages a second, we are uploading 12.89 KBps per player. Now, this may not sound like a lot, but consider this: as the player cap for a single game increases, so does the required bandwidth, in a linear fashion. Given enough players or game instances, these numbers become sobering very quickly.
You may have already noticed that every message we send comprises of exactly eight values per player. If we define a set ordering of these values, we can dispense with the structure and just rebuild the state with the data once we receive it on the client, bringing us down to 8.61 KBps per player. You will also notice that this is harder to parse at a glance. However, the question remains—can we do better?
An Aside on Text Encodings
Before we continue, it is imperative to understand how WebSocket actually transports data. WebSockets originally only allowed UTF-8 data to be transmitted on the wire. Then in April of 2011, the hybi-07 draft of the WebSocket protocol introduced the option to transfer binary data. The catch here is that socket.io does not currently support binary WebSocket frames. I’ll discuss this more later, but keep this in mind when choosing a WebSocket implementation for node.js.
For those unfamiliar with the Unicode Standard, UTF-8 is a variable-length encoding. This fact will become important when we calculate exactly how big our messages are. The other caveat here occurs when the WebSocket protocol receives invalid UTF-8—the connection must immediately be failed and the connection closed. This includes invalid byte sequences and invalid code points and needs to be kept in mind when trying to encode data with UTF-8. Also worth noting is that JavaScript uses UTF-16 and will not error if you attempt to create an invalid string.
Getting Down and Dirty: Looking at the (Naughty) Bits
If you’ve been around computers, code, or programmers for long enough, you may be privy to the fact that underneath it all, those numbers are represented by a bunch of bits. You may even know that the Numbers in JavaScript are represented by the IEEE 754 double-precision floating-point format. But if you don’t, the main takeaway is that they occupy 8 bytes of memory. This is a lot less than the 20 characters (and therefore 20 bytes) some of the Numbers use in JSON, and we’re going to look into this binary representation using typed arrays.
When we use typed arrays, we can more closely examine the binary form of the data. Behind each typed array we create is an ArrayBuffer object that holds the actual bits for the typed array. These ArrayBuffers are chunks of pure bits—they have no notion what kind of data they hold or what format it is in. In order to make sense of this pure data, we need to impose some context. We can create “views” to accomplish this. Here is an example of what you might see in node.js on a little-endian machine.
We can see the eight individual bytes that compose the Number that is
15.290663048624992. We can then convert these into an eight
character string using String.fromCharCode. We can then compress the
entire game state in the process shown below.
Our resulting message is 128 characters long, and because it will be UTF-8 encoded, ends up being 170 bytes. Once we add our overhead, we have slimmed our bandwidth usage down to 5.86 KBps per player. That’s a 54% reduction from our initial naïve approach!
How Low Can You Go?
There are further ways to compress your data, including actual compression algorithms, and we will go into more detail for a few of these techniques. Some of these will apply very well generally, but there are some techniques here that won’t fit your requirements, may end up being too costly (in clock cycles or development time), or may even inflate your data. Feel free to mix and match these techniques, but as with optimization in general, be sure to test with data that is representative of your real world data.
Too Much Precision?
It is possible that the data the server is sending to the clients is too precise. Do you really need to send double-precision values? Will just single-precision work? Can we send them as 16 bit or even 8 bit integers? Do we need to even send it at all? These are all questions that will depend heavily on the application, but can help cut down a lot of the data.
In our example, we end up encoding the ids in the game state as
double-precision values. However, when we examine our application, we
see that they are just meant as an unique identifier within the
game. Let us assume that we have a player cap of four players. In that
case, an 8-bit integer is more than enough for our needs. Then,
assuming we use a server-client model where the client is simply a
dumb renderer, we can definitely get away with using single-precision
numbers for the position and rotation values. We are then left with a
string of 58 characters, totaling 75 bytes. Add our overhead, and we
have 3.08 KBps per player.
The Overhead
With our last optimization getting as low as 75 bytes, those 30 bytes
of overhead really hurt. So what exactly are they doing for us that is
worth holding on to? You will recall that part of this overhead
includes the event name that the event system uses. We can certainly
pick shorter event names, but that reduces readability of the code,
and there are still bits of JSON in there from using emit.
The solution is to bypass all of this. socket.io allows you to skip all the nonsense and just use bare-bones messages with the “message” event. We can then recreate the event system on top in a less verbose manner by using something akin to C-style enums. We put this enum in code shared between the server and client, and then manually dispatch events when we receive them.
There is a lot of flexibility in terms of how this dispatch layer can be architected. Here, we make use of EventEmitter2’s wildcard functionality to mimic the original interface, allowing us to accept strings as events, encode the message type, and then send it down the wire. Although socket.io will still add 4 characters up front, the important thing is that we’ve reduced our overhead from 30 characters down to 5 characters. Applying this to our third example drops our message size from around 200 bytes to 175 bytes and our bandwidth down to 5.13 KBps per player.
Delta Compression and ZigZag Encoding
With names out of a young adult sci-fi novel, delta compression and ZigZag encoding are compression techniques that are very dependent on the data that you run them on.
Delta compression is a technique used when unsigned integers are stored in a variable-length encoding. By storing the difference between the current value and the previous value, we obtain smaller values which use fewer bytes. Now, when I use the terms current and previous, this can mean over time, between messages, or within a single message, between the sequence of values.
<pre id="figure-10">
var sequence1 = [ 0, 1, 2, 3, 4, 5, 6 ];
var deltaSeq1 = [ 0, 1, 1, 1, 1, 1, 1 ];
// Initial unsigned sequence. 12 bytes.
var sequence2 = [ 150, 160, 155, 140, 153, 151 ];
// Signed delta compressed sequence
var deltaSeq2 = [ 150, 10, -5, -15, 13, -2 ];
</pre>
To understand how this actually saves us bytes requires that we go
back to our encoding. If we encoded sequence2 as UTF-8, they would
all require two bytes. Remember, all code points from 128 to 2047
require two bytes in UTF-8. However, we run into a snag when we
encode the delta compressed sequence.
<pre id="figure-11">
var deltaSeq2 = [ 150, 10, -5, -15, 13, -2 ];
// Delta compressed sequence as unsigned
var unsigned2 = [ 150, 10, 251, 241, 13, 254 ];
</pre>
Representation of negative numbers using two’s complement interferes with our goal of getting small numbers. What we want is for numbers with a small magnitude to be mapped to small unsigned values, and therefore less bytes. This is where ZigZag encoding comes in. The Google Protocol Buffer documentation has a great description (and code), but the general idea involves “zig-zagging” back and forth between positive and negative numbers. Our final result then only has an initial value that uses two bytes, with the rest of the sequence using a single byte for each value.
var sequence2 = [ 150, 10, -5, -15, 13, -2 ];
// Final unsigned sequence, delta compressed
// and ZigZag'd. 7 bytes.
var zigzagdlt = [ 150, 20, 9, 29, 26, 3 ];
base128 Encoding
Another way that we can maximize the number of one byte characters is to ensure that it will always be so. By taking an ArrayBuffer and serializing 7 bits at a time to a string, we guarantee that all code points will be less than 128 and all the characters in the UTF-8 stream will be one byte in length.
This is an interesting technique, because we have essentially changed our data encoding to be a fixed-length encoding. Techniques like delta compression no longer have any affect if we use base128 encoding. In terms of compression performance, every byte can only be used to store 7 bites of data, so the encoded data will be 8 / 7 ≈ 14.3% larger than the binary representation of the data. This is better than the expected value of 50% when encoding uniformly random 8-bit integers, but your mileage may vary, depending on your data. However, before you jump to implement a base128 encoder, you may want to consider using binary transport.
Binary Transport
Ah, now we’re really getting down to brass tacks. Here, we skip all the inconvenient little transformations and ship entire typed arrays down on the wire. Unfortunately socket.io does not support sending binary data because the other fallback transport methods have issues with binary data, which may be a problem for some applications. But fear not, because the WebSocket library that socket.io uses, ws, does in fact support sending binary data, as do other WebSocket implementations like faye-websocket and WebSocket-Node.
There is a potential pitfall that using binary data can lead to. To initialize a view onto an ArrayBuffer, the view must be byte aligned to the beginning of the ArrayBuffer. That means that you can only put a 64-bit floating-point number at intervals of eight bytes and 32-bit integers at intervals of four bytes. We need padding to ensure byte alignment for the typed arrays, or a means of packing values cleanly. There is also the need for having the entire typed array allocated, although this will generally speaking be relatively small. However, variable length data, like arrays, may present issues. Nonetheless, between strictly base128 encoding and just sending the binary, we save the need to encode the data with bitwise operations and only need 7 / 8 of the space, potentially cutting down ≈12.5% of the bandwidth.
WebSocket Deflate Extension
The last technique I will cover is the use of an actual compression algorithm. Older drafts of the WebSocket specification described a deflate-stream extension that applied compression to the stream. However, there were many potential issues with this extension. Len Holgate sums up the pitfalls regarding deflate-stream, which was pulled in 11th draft of the specification (§9.2.1). There is an alternative, however, and that is the per-frame DEFLATE extension.
The good news is that the deflate-frame extension landed in WebKit back in February. The bad news is that there is not yet a WebSocket implementation in node.js that implements the extension, although that will hopefully change really soon.
The caveat with a compression extension is that the browser has to also support the extension. As such, the target browser of your application will determine the efficacy of this technique.
Final Thoughts
As I had stated in the opening statements of this section, these techniques have varying degrees of efficacy for different data sets. This is then compounded by the fact that combining these techniques and the ordering thereof will have differing results. I‘ve been hesitant to include a graph of the performance, as it may trick the unwary into thinking that there is an ultimate punchline. The answer to that heavily involves not only your data, but also your target platforms/browsers and other constraints.
Conclusion
If you’ve managed to make it this far, chances are that this topic is of great interest (or concern) to you. I would recommend closely examining the technologies you’re using. If you don’t need the robustness of socket.io, consider using a pure WebSocket implementation. Finally, if you need more ideas for compression, consider looking into other areas for inspiration. For example, the demoscene uses many techniques to heavily compress vertex data for meshes. It is also possible to compress your data yourself without relying on deflate-frame, although runtime performance needs to be considered here as well. And as with all optimizations, don’t forget to test!

Comments